记住用户名密码
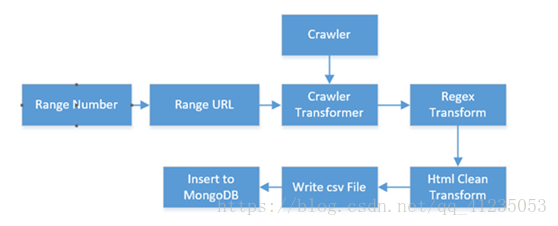
etlpy是python编写的网页数据抓取和清洗工具,核心文件etl.py不超过500行,具备如下特点
爬虫和清洗逻辑基于xml定义,不需手工编写
基于python生成器,流式处理,对内存无要求
内置线程池,支持串行和并行处理
内置正则解析,html转义,json转换等数据清洗功能,直接输出可用文件
插件式设计,能够非常方便地...

使用场景,本地服务器一直在运算数据,实时发送这些数据给客户端,本地局域网内其他客户,可以实时连接服务器,获取服务器数据,互不影响。
python2服务端
#-*- coding:utf-8 -*-
__author__ = 'xiaomei'
import socket
import SocketServer
HOST = '1...

beautifulsoup解析页面
from bs4 import BeautifulSoup
soup = BeautifulSoup(htmltxt, "lxml")
# 三种装载器
soup = BeautifulSoup("<a></p>", "html.parser")
### 只有起始标签的会自动补全,只有结束标签的会自动忽略
### 结果为:<a></a>
soup = Beautiful...